欢迎来到硕迪科技官网
400-009-9965
solidbi@shuodizhixin.com
许多做数据管理,数据治理的同学,经常会被数据库(仓库)中大量繁杂的数据表困扰,很多数据表并不是存储必要的基础数据的,而是在计算和查询中产生的中间表,这些中间表,经过常年累月的积累,往往会达到一个恐怖的数量级,严重的影响了数据库的管理和性能,而且这些中间表,又不敢随便删除,因为有的仍然在用,有的不知道还有没有用,随意删除很有可能就会影响业务,这时只能被迫的给数据库扩容了
而这些让人苦恼的中间表,很大一部分就是因为前端的报表业务所产生的
报表怎么产生的中间表?
原始数据量很大时,报表直接基于原始数据计算汇总信息时的性能会很差,用户体验恶劣,这时,通常的做法就是先把一些汇总结果事先计算出来,报表再基于这些中间结果做呈现,用户体验就会好很多,这些中间数据就会以中间表的形式存储
原始数据到最终呈现的数据计算过程复杂时,一个 SQL 算不完,那就得先把中间结果存一下,然后再继续算,这就产生了中间表
或者很多报表都得基于某个复杂计算的结果来做,每个报表都各自算一次,很繁琐,还得频繁占用数据库资源,那就可以用一个中间表先把结果存下来,供多个报表来用,这也会产生中间表
大数据时代,报表的很多数据来源都是来自库外的,比如文本存储的数据,或者其他不太好计算的非关系数据源,常用的做法是把库外数据定时导入到数据库中,然后就能和数据库内的数据一起运算了,这就又产生了中间表,而且,有些多层的 json 或 XML 格式,在关系数据库中还要建立多个关联的表来存储,就不是多一个中间表的问题了
这些中间表,都是因为报表而产生的
从上面中间表产生的原因,我们可以看出,它其实是为了解决数据计算本身的难题而诞生的,属于解决问题的有功之臣,但是当它的数量一旦多起来以后,就把自己也变成了一个难题
大量的中间表,会占用很大数据库容量,甚至有些已经不用的中间表还在定时更新数据,在不断的变大,那么多表,我们又不知道哪个有用哪个没用,不敢乱删,只能放任其不断的增多、变大,容量告警时,就只能被迫进行数据库的扩容,而扩容,是需要很大成本的,不管是横向还是纵向
中间表相关的运算还会占用数据库宝贵的计算资源,影响数据库的性能,每个中间表都涉及计算,重要的不重要的,有用的没用的,都在抢资源,量大的时候就会影响数据库关键业务的计算,带来严重的性能问题
中间数据的思路是没有大问题,有问题的是把它们存到数据库里这个环节
那存到库外不就可以了吗?这个想法很好,但之前因为技术限制,存到库外后会让续的计算变的复杂,很少有这么做的
中间表是要再计算的,基于中间表查询的报表还要进行数据过滤,有的还要再次汇总,还可能涉及关联计算,这些操作在数据库里通过 SQL 完成很简单,但是文件没有计算能力,要实施这些计算只能硬编码,用 JAVA 来做,使用 JAVA 来做集合运算又非常麻烦,远没有数据库(SQL)方便,所以很少有人把中间表存在库外
但现在有新技术了,集成了 SPL 集算器的硕迪报表,让这种想法变的可行了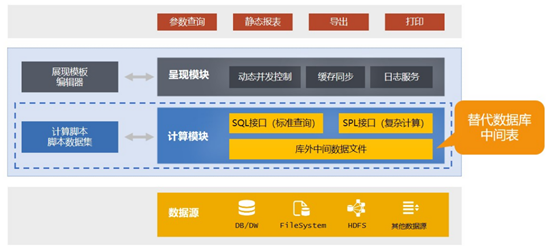
SPL 是一款流行的专业的数据计算处理工具,很多项目开发商都在用,因为它不仅好用,而且还免费,开源,是常年做项目,总需要做数据处理的工程师的好帮手
集成了 SPL 以后,硕迪报表就有了计算文件数据的能力,这样数据库的大量中间表就可以都移到了库外了,用普通的 TXT 或者其他方式存储都可以,也可以用 SPL 独有的的更高性能的二进制文件,报表直接可以对接他们来算
比如要查询 2012 年销售总额超过 800 万的地区及销售金额
就可以提前汇总数据,并把中间结果用文件存储的方式存储,而不需要放到数据库中

然后报表直接针对文件数据查询计算就可以
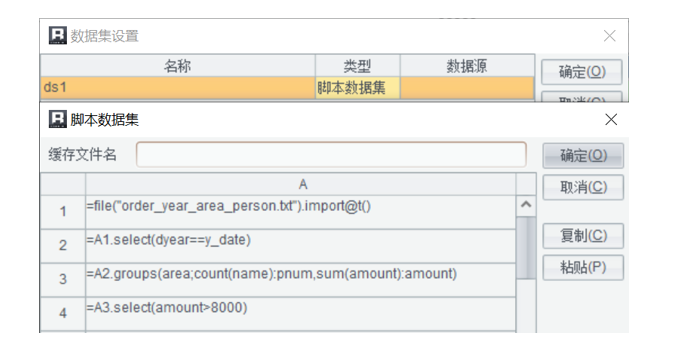
=file("order_year_area_person.txt").import@t() // 读取文件数据(以文本为例)
=A1.select(dyear==y_date) // 根据年份参数过滤数据
=A2.groups(area;count(name):pnum,sum(amount):amount) // 按照地区分组汇总人数和销售额
=A3.select(amount>8000) // 选出销售额大于 8000 的记录
可以用 SPL 的脚本直接计算,如上图,也可以用 SQL 来计算,如下图
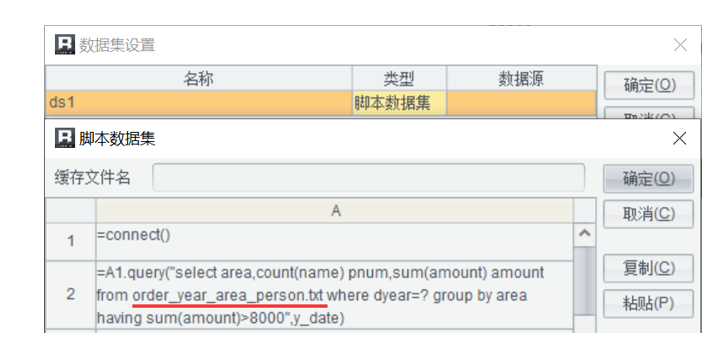
=connect()// 连接文件系统
=A1.query("select area,count(name) pnum,sum(amount) amount from order_year_area_person.txt where dyear=? group by area having sum(amount)>8000".y_date) // 执行标准 SQL 查询文本
//SPL code from https://c.raqsoft.com.cn/article/1667989949404
=connect() // 连接文件系统
=A1.query("select area,count(name) pnum,sum(amount) amount from order_year_area_person.txt where dyear=? group by area having sum(amount)>8000".y_date) // 执行标准 SQL 查询文本
SPL 具有完整的计算能力,高效又简单,文件存储数据不好计算的困扰就这么解决了
而且文件存储还易于管理,性能更好
文件存储易于管理
中间结果存到库外后,数据库就仅需要存储少量原始数据表就可以,数据库自身的管理压力就会变小,都转移到了库外文件上了
而库外的文件,就是普通的计算机文件,天然就便于管理,可以通过系统的树状目录进行存储,文件都跟着应用走,目录清晰,使用和管理都很方便,不会出现交叉引用相互耦合的情况,报表弃用或者应用下线,相应的中间存储文件就可以删除,再也没有想删不敢删的苦恼了
文件存储性能更好
文件系统更靠近底层,更接近磁盘,IO 性能本身就好于数据库
如果用 SPL 的二进制存储方式,效果会更明显,因为 SPL 的文件格式更紧凑,对于只读的中间数据,使用文件存储时不需要考虑再改写,可以更为紧致并采用一定的压缩手段,而且在访问时也不必考虑事务一致性,机制大为简化,这样就能获得更好的吞吐性能了
对于数据量大和计算复杂导致的中间表,可以用文件来解决掉了,而对于多样性数据源带来的中间表又该怎么办呢?
也没问题,SPL 还支持多样性数据源,可以直接连接各类数据源进行多源混算,不管你存在哪里,有没有计算能力等,都不需要再把难算的数据导入到关系库中了形成中间表了
对于报表应用而言,中间数据的存在是有价值的,中间数据的思路也是正确的,但它多起来后的弊端也是显而易见的,硕迪 SPL 方案并没有让中间数据消失,只是把中间表移到了库外,然后再利用自己的计算能力来完成计算,这样既能发挥中间数据的价值,又避免了它存到库内的麻烦,就让整个中间数据的方案更加完善通畅了


