欢迎来到硕迪科技官网
400-009-9965
solidbi@shuodizhixin.com
现代应用已经进入多数据源阶段了,不再是一个单一的数据库包打天下,一个应用中会涉及除关系数据库外各种数据源,如文本文件类数据、NOSQL、多维数据库、HTML Webservice 等等,即使是关系数据库,也可能不止一个
应用这样了,那么应用中的报表自然也会涉及到多样性的数据源了
现在的报表,基本都是用报表工具来做,很多报表工具都号称支持多数据源,是不是能解决这个问题呢?
其实只能搞定一点点
简单的说,来自关系数据库的多源数据都比较好搞定,不管是多表,还是多库,都很简单,用 SQL 把各个来源的数据都取出来,放到报表中去关联、计算、呈现就可以
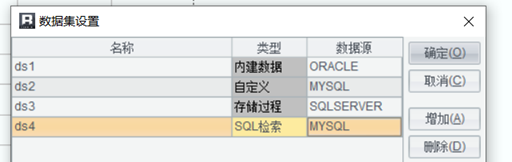

这样的多源数据,好一点的报表工具都可以轻松应对
也可以简单的说,不是单纯的关系数据库的多源数据,报表工具都不太好做

进入大数据时代以来,数据不仅是大了,而且存储的方式也多了,除了传统的关系数据库外,还有
1.TXT/CSV、Excel、JSON/XML 等文件;
2.MongoDB、Cassandra、HBase、Redis 这些 NoSQL 数据库;
3.HDFS 等分布式文件系统;
4.webService;
5.ES、Kafka 等其他数据源形式
文件类的某些报表工具还能搞定,但也只限于读,而不会算,只能先全部读入到报表中,然后再利用报表的计算能力来计算处理,数据量大时,读取的效率和空间容量都可能会成为问题,(极个别的工具可以边读边汇总过滤,还能并行流式读取,会好很多);其它类的数据源大部分报表工具就连读都不会了,因为没有标准,每家有各自的 API,想要读取,大部分都得通过 JAVA 自定义数据集的方式了
读取都比较费劲,而这些数据常常在业务逻辑上又有关联,做报表的时候大部分时候都会涉及到多个数据源之间的关联混算,单凭报表工具提供的多源关联能力处理起来就更困难了
报表工具解决不了,但也难不倒工程师,因为工程师会编码,没有什么是编码解决不了的,
工程师可以先把异构的数据变成同构的,比如把文件的数据先导入到 RDB 中,由 RDB 计算后再给报表用,而那些不会读的,就只能再一次依靠所有报表工具都提供的所谓自定义数据原接口了用 JAVA 读入并处理好,再传给报表
项目中,很多困难的多源混算情况,都是这么处理的,都能搞定,但是这么做其实弊端很多
异构变同构,其实大部分时候是把不同的数据强行装入到常见关系数据库中,然后再利用 SQL 的方式来处理计算,这样做,首先得考虑数据库本身的管理和压力,管理上是否允许这样操作,容量是否够,每次遇到这样的库外数据都要往数据库中放?
然后还得考虑时效,数据的导入都需要时间,量少的耗时短可能无所谓,量大的可能进度都被耽误了,而且一般业务数据都是实时变动的,导入数据的方式也基本很难保证数据的实时性,还有些变不了或者变起来极困难的,像 json/xml 多层数据(mongodb 也是这种),要建很多表,想变都变不了
JAVA 处理的话,要好很多,不用考虑入库的一系列问题,实时性也可以保证,但是开发成本高,还会破坏应用架构
JAVA 开发人员的成本本身就高,然后 JAVA 计算数据的能力还很弱,写起来工作量很大,简单做个求和运算都需要写数行代码的循环来实现,更别说逻辑复杂的运算了,动辄几百行的代码,一个报表还可以承受,报表一多,就承受不了这样的高成本了
另外 JAVA 代码需要和项目应用一起编译,也会带来报表和应用高耦合的问题,还会影响报表本身热切换的能力
如果报表工具提供处理复杂多样性数据源的能力,那问题就可以迎刃而解了,就不需要再来回倒腾数据或者 JAVA 硬写了
硕迪报表集成SPL 集算器以后就具备了这样的能力
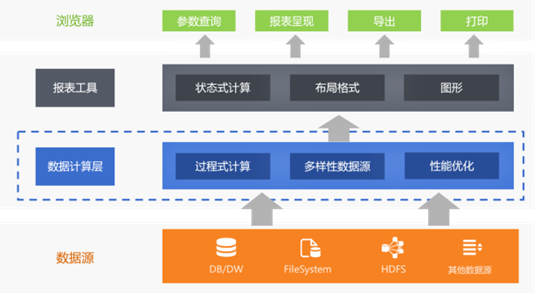
SPL 是一款流行的专业的数据计算处理工具,很多项目开发商都在用,因为它不仅好用,而且还免费,开源,是常年做项目,总需要做数据处理的工程师的好帮手
集成 SPL 后,硕迪报表相当于多了一个计算层,这个计算层支持常见的各类数据源,可以同时计算来自不同数据源的数据,不管它是同构还是异构
比如 JSON 和 ORACLE 混算
=json(file("/data/EO.json").read()) JSON 数据
=A1.conj(Orders)
=A2.select(Amount>1000 &&Amount<=3000 && like@c(Client,"s")) 条件过滤
=db.query@x("select ID,Name,Area from Client") 数据库数据
=join(A3:o,Client;A4:c,ID) 关联计算
再比如 MongoDB 和 CSV 关联运算
=mongo_open("mongodb://127.0.0.1:27017/mongo")
=mongo_shell(A1,"Orders.find()").fetch()
=file("Employee.csv").import@tc()
=mongo_close(A1)
=join(A2,SellerId;A3,EId)
=A5.new(_1.OrderID,_1.Client,_2.Name,_2.Gender,_2.Dept)
原本要做各种转换把数据导入到库里,或者用大段的 JAVA 来写,现在简单几行 SPL 代码就轻松搞定了。


